Syncing millions of records a day to BigQuery: our experience moving from GAE to GKE
This week we moved one of our analytics workloads from Google App Engine (GAE) to the Google Kubernetes Engine (GKE), and wanted to share our experience in simplifying a setup that syncs millions of records to BigQuery each and every day.
Prelude
At Namshi, we run all kinds of workloads, from internal apps used by some of our departments to customer-facing APIs.
Recently, we’ve come up with a particular challenge: we wanted to track a high volume of events that happen on our mobile applications, and our go-to choice was to rely on Google Tag Manager to send these events to Google Analytics.
Long story short, the events we’re trying to track aren’t your usual pageview, or click on a product page, but a more casual action users do while browsing our apps — around 30M of them on a slow day. As soon as we started sending this additional traffic over, GA started rate-limiting us and it became clear we wouldn’t be able to piggy-back on Google’s analytics offering for this kind of tracking.
The next natural solution was to build our own event collector, something that proved to be extremely interesting: even though we’re not going to dig deep into our code (it’s really not that crazy!) we believe the experience taught us a lot.
Architecture
As soon as we decided to build our own collector, we were faced with 2 simple questions: where to store this data and what platform to use?
To begin with, we benchmarked BigQuery’s streaming protocol and found it could easily sustain the amount of data we wanted to transfer so, considering we’re pretty well versed with BigQuery as we use it for a plethora of other projects, this was a quick and easy decision.
Then it came the time to decide on which platform we would build the app itself, and this was, again, a fairly easy decision: what we were looking for was a fast, pragmatic platform that would allows us to build high-performance webservers and integrate with BQ seamlessly. Our choice was Golang, as it allows to build incredibly efficient servers and has a very well-built package to interface directly with BigQuery.
As I mentioned, our code was fairly simple: a request comes in, we pull parameters from the URL and sync it into BigQuery.
// Code is simplified as our full codebase
// does things you don't really need to get into... ;)
type Event struct {
Data string
Ts time.Time
}
http.HandleFunc("/track-me", func(w http.ResponseWriter, req *http.Request) {
client, err := bigquery.NewClient(ctx, PROJECT_ID)
if err != nil {
// ...handle error...
}
u := client.Dataset(DATASET).Table(TABLE).Uploader()
events := []*Event{
{Data: req.URL.Query(), Ts: time.Now()},
}
if err := u.Put(ctx, events); err != nil {
log.Printf("error: %s", err)
}
io.WriteString(w, "ok")
})Now, the app is definitely not optimized, as it tries to sync to BigQuery at every request — which is a (fairly) expensive operation: we had a reason for keeping it this way, a reason called Google App Engine.
On GAE
Since we were worried about the scalability of our hosting platform, we decided to deploy this application on Google App Engine, an infinitely scalable platform ran by Google.
The tricky bit of GAE is that it “forces” you to run all of your application logic within a single request/response: everything you want to do needs to be completed before you return a response to the client. This is definitely an acceptable trade-off in a lot of use-cases, as it guarantees that Google can spin instances up and down at will, but didn’t work too great for us as it really added an expensive operation in our route (syncing to BigQuery).
Ideally, we would have liked to be able to execute the sync in background, but App Engine has a fairly complex implementation of background jobs that we didn’t like as much, as we wanted to keep the setup as simple as possible.
We went live with a working app within a day, but we immediately noticed a problem, as latency was much higher than we expected:
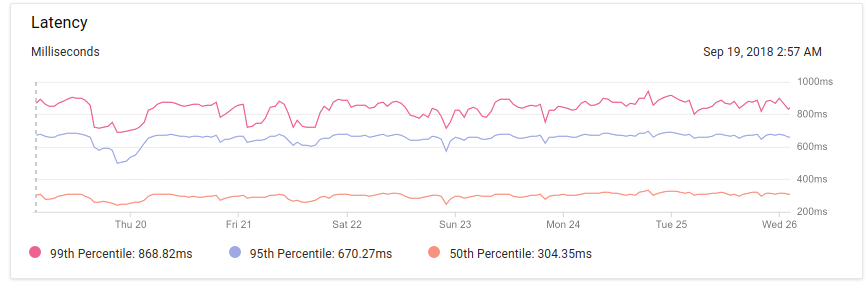
A median of 300ms for an app that simply receives a request and syncs it to BigQuery seemed way higher than we expected: we eventually didn’t bother as much as what we needed wasn’t high-performance, but rather high-scalability, and GAE fit the bill perfectly.
After a couple weeks, though, we noticed another interesting problem: since the app wasn’t as efficient as we thought, lots of GAE instances were being used to keep up with the amount of traffic we were receiving, something that reflected on our GCP bill right away:
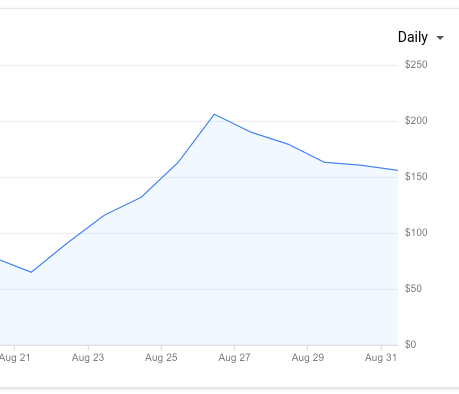
This little tracking app was costing us around $150 a day ($4500 per month), way more than we initially budgeted: time to review the setup and come up with a more efficient way to use Google’s servers, at a fraction of the cost.
GKE
We are very big on Kubernetes, so the very next step was to try to move our application to the GKE, Google’s hosted Kubernetes service.
The idea was very simple: let’s rewrite the app so that it batches requests to BigQuery, let’s setup a small k8s cluster with node autoscaling and let’s set the right scaling policies (HPA) for our pods.
Rewriting the app was very easy: instead of syncing to BigQuery at each request, we simply created a channel that buffers up to X events, and syncs them in batch once the buffer’s filled up:
var (
MaxWorkers = 10
MaxQueue = 10000
BatchSize = 100
)
type Event struct {
Data string
Ts time.Time
}
func main() {
jobs := make(chan Event, MaxQueue)
for w := 1; w <= MaxWorkers; w++ {
go worker(jobs)
}
http.HandleFunc("/track-me", func(w http.ResponseWriter, req *http.Request) {
jobs <- Event{Data: req.URL.Query(), Ts: time.Now()}
io.WriteString(w, "ok")
})
log.Printf("Server listening on port %s", os.Getenv("PORT"))
log.Fatal(http.ListenAndServe(":"+os.Getenv("PORT"), nil))
}
func worker(events <-chan Event) {
ctx := context.Background()
client, err := bigquery.NewClient(ctx, PROJECT_ID)
if err != nil {
panic(err) // YOLO!
}
buffer := []*Event{}
for e := range events {
u := client.Dataset(DATASET).Table(TABLE).Uploader()
buffer = append(buffer, &e)
if len(buffer) == BatchSize {
log.Printf("Flushing %d events to BQ", BatchSize)
if err := u.Put(ctx, buffer); err != nil {
log.Printf("%s", err)
}
log.Printf("work done")
buffer = []*Event{}
}
}
}Next in line was to create the k8s cluster, which was an extremely simple operation from GKE’s interface: we deployed our pods, setup an ingress and… …boom, the app was live under a different URL!
Last but not least, we wanted to make sure that spikes in traffic were taken care of, both from a memory and cpu standpoint:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: tracking-app-cpu
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: tracking-app
minReplicas: 4
maxReplicas: 100
targetCPUUtilizationPercentage: 20
---
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: tracking-app-memory
spec:
scaleTargetRef:
apiVersion: apps/v1beta1
kind: Deployment
name: tracking-app
minReplicas: 4
maxReplicas: 100
metrics:
- type: Resource
resource:
name: memory
targetAverageUtilization: 30Once the HPAs were ready, we switched our tracking URLs and…
Results
Where do we start? Well, since we’re all computer geeks at the end of the day, let’s look at our response times, now monitored through NewRelic:
![]()
Our 99th percentile is at less than 0.2 milliseconds which is definitely more like what we initially planned — we finally nailed it!
As far as cost is concerned, this new cluster (which, again, manages more than 30M events a day) costs us between $300 to $400, a ~90% price reduction compared to the cost of running the same application on GAE.
If we look at the pricing report from the GCP project in question you can clearly see the cost reduction as soon as we deployed the application on the GKE:
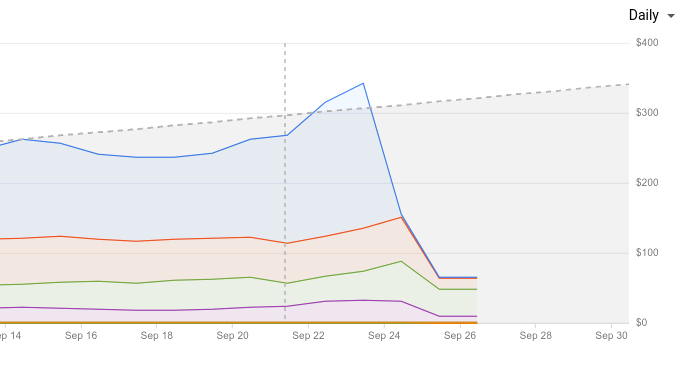
We also take advantage of a simplified setup where
we can manage the cluster through the good old kubectl,
and deployments are much simpler than GAE (if you ever
used GAE you know what I’m talking about…).
Conclusion
The goal of this post is not to say that GAE is terrible, or that GKE is the best hosting platform out there: it merely is a report based on our own experience building a scalable event tracking system that we moved from one platform to the other. GAE is surely quicker to setup and includes additional abstractions that the GKE forces you to take care of (load balancing and SSL, just to name a couple of them), so we recommend to think about your use case and make a reasonated choice.
We truly hope you enjoyed this post! By the way, we’re hiring!