How Namshi builds Docker containers through Docker containers
When we started experimenting with Docker, its environment was pretty new: private registries weren’t en vogue and the DockerHub seemed to be the only decent alternative to store images and build your delivery pipeline on, even though it could take up to 15 minutes to get a simple image pushed to S3 from the Hub.
We wanted a cheap, reliable, fast build tool that could fit our delivery pipeline: we wanted our code to seamlessly go from an engineer’s machine to production; we wanted to build containers in seconds; we wanted stability and a (almost) zero-configuration approach.
At the end of it, we wrote a build system for containers that goes Open-Source today: in this post we are going to look at the reasons behind it, how it works (for us), how it can work (for you) and what are our plans for the future.
Why the heck did you write a build system to begin with?
First off, to call this tool a build system seems to be a bit pretentious: at the end of the day we only wanted a fast and reliable way to run docker builds on a remote machine and push them to our own private registry.
We haven’t built our own DockerHub, CodeShip, Shippable or Travis-CI: it is not our philosophy. We hate to re-invent the wheel and only do so if we find a roadblock ahead.
When we started working with containers, our first choice was to simply rely on the hub, which turned out to be quite frustrating; we can summarize our experience with the hub with these words:
Docker Hub also has an automated build system which detects new commits in your repository and triggers a container build. It is also completely useless for many reasons. Build configuration is restrictive with little to no ability for customisation, missing even the basics of pre/post script hooks. It enforces a specific project structure, expecting a single Dockerfile in the project root, which breaks our previously mentioned build workarounds, and build times were horribly slow.
As much as we love the guys behind Docker (and the hub as well!),
we tend to agree with the words of the above post: the hub is slow
and the fact that you need to manually configure which branches
you can build off from it’s a poor design choice. A developer branches
off master, creates $devname-patch-1, pushes and… …hey,
nothing gets built: we need to log into the hub and tell it that
it has to build from that new branch as well. No good.
We looked around but, 6 months ago, CodeShip wasn’t planning anything (they just recently launched a private beta, which we’re eager to try out) and Drone.io was still too quirky (it still is).
Then we decided to spend 2 evenings on a prototype to trigger builds from github hooks: we hacked a very basic software (which runs in a container) that could talk to the Docker demon and tell it that it needs to build from a Dockerfile. We deployed it in our internal infrastructure, moved our deployment script from pulling images from the hub to our private registry (where the builder pushes) and never looked back.
We now have some builds that run in 5 seconds or so.
Thank you, Roger.
Welcome Roger!
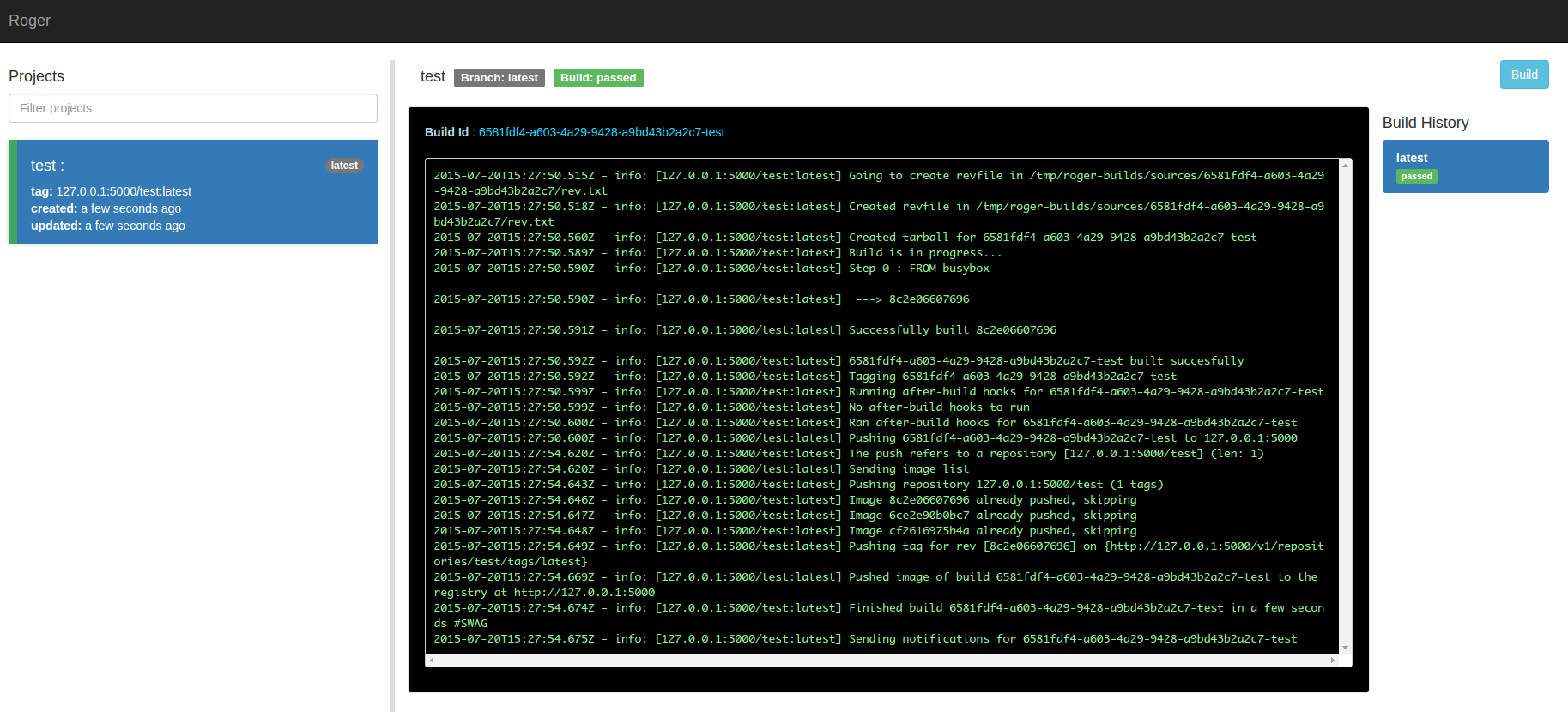
Roger is a JavaScript app (the server is built with Node, the client with React) that runs in a container and tells Docker to build images, at will: you can trigger builds manually or simply setup some hooks so that whenever you push Roger is going to trigger a new build.
We are making it publicly available today, after weeks spent on discussing if it was worth it and then refining the tool for the public: we don’t think Roger is the Next Big Thing but we are hopeful that the approach we used could inspire some of you and solve the same kind of problems that bugged us.
To run roger, simply create a minimal config.yml file:
auth:
dockerhub: # these credentials are only useful if you need to push to the dockerhub
username: user # your username on the dockerhub
email: someone@gmail.com # your...well, you get it
password: YOUR_DOCKERHUB_PASSWORD
github: YOUR_GITHUB_TOKEN # used to clone private reposThen clone the Roger repo, build the container and run it locally:
git clone git@github.com:namshi/roger.git
cd roger
docker build -t namshi/roger .
docker run -ti -p 6600:6600 \
-v /tmp/logs:/tmp/roger-builds/logs \
-v $(pwd)/db:/db \
-v /path/to/your/config.yml:/config.yml \
-v /var/run/docker.sock:/tmp/docker.sock \
namshi/rogerYou now have Roger up and running on your localhost: time to trigger our first build!
Head over to localhost:6600/api/build?repo=https://github.com/namshi/test-build
to schedule your first build, you should see
a simple confirmation message:

and, on the web interface at localhost:6600:
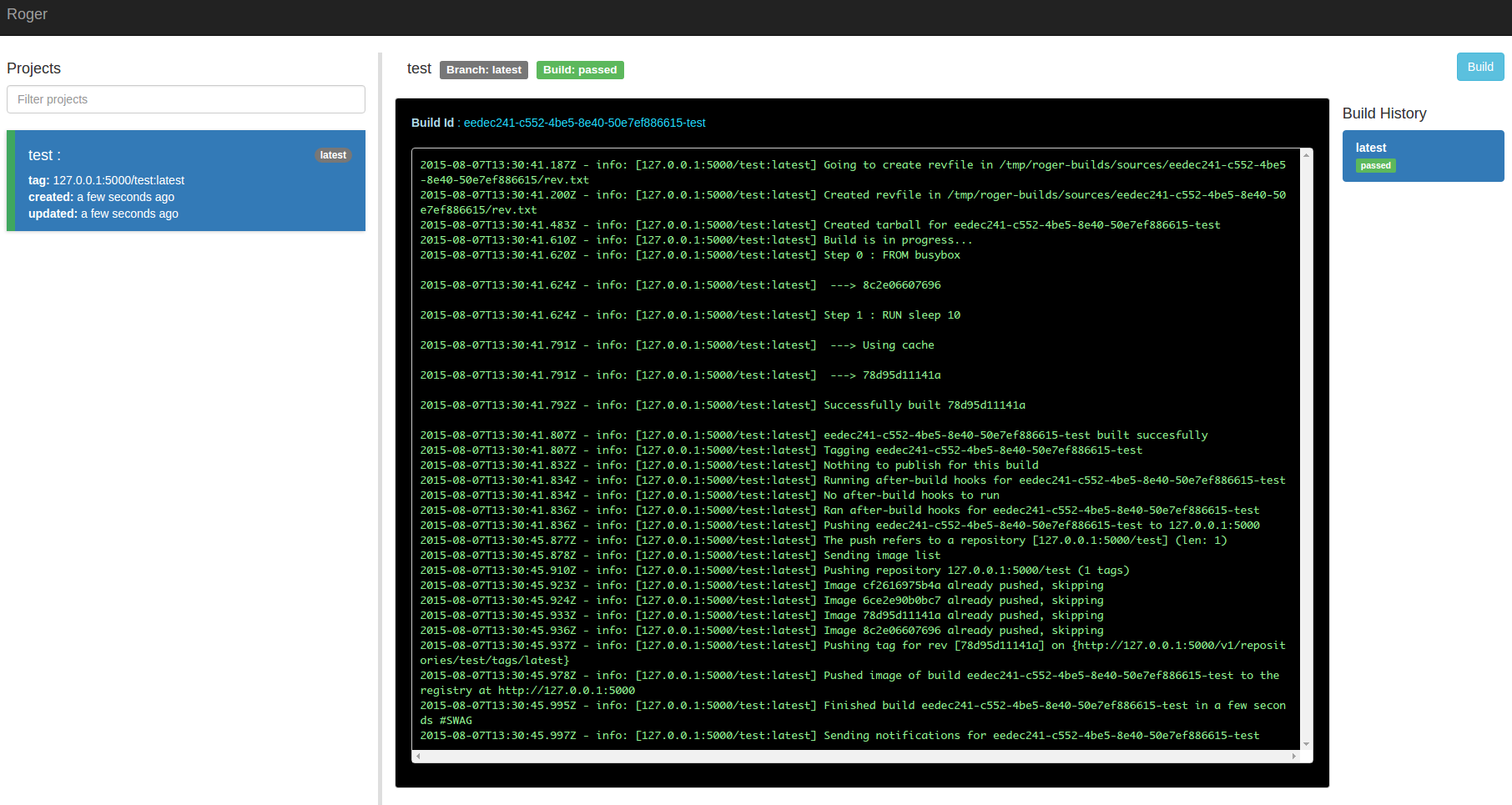
Eureka!
Wondering how Roger knows how to build the given
repo? It first clones it and then reads a build.yml
file in the root of the repo, just like
this one
(don’t worry about understanding how the build.yml works now,
we will have a look at it later).
Triggering manual builds wouldn’t be much fun on the long run, as you will probably want your images to be built everytime someone pushes to your repo.
You can do that by setting up a github hook, in your repo, that will hit Roger:
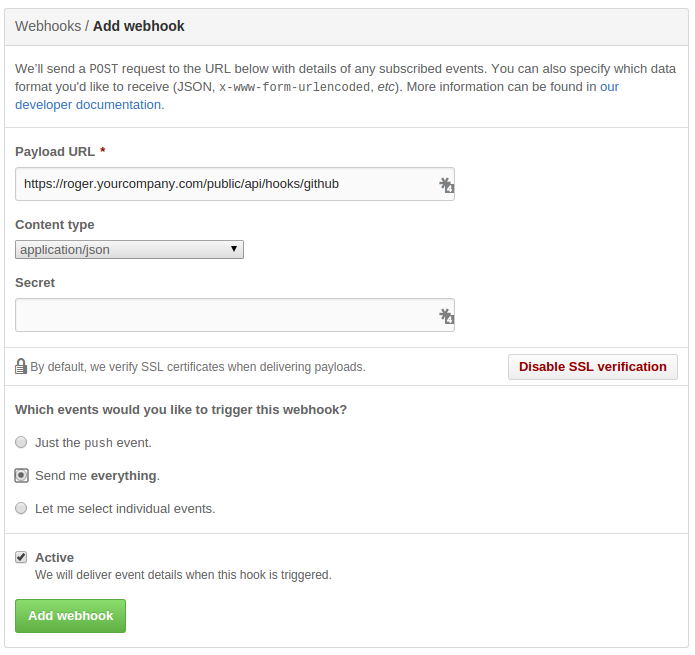
That simple: now, everytime you push or create a new tag in your repo, Roger will create a new image.
What is really interesting about Roger is the fact
that you really need a very minimal configuration:
a github access token in your config.yml, a build.yml
in your repo and you’re done. We wanted to build
our system so that we wouldn’t have to spend too much
time configuring it, so that it could be smart enough
to infer most things from the outside.
A few use cases
Say that your github repo actually contains 2 projects, a client and a server:
redis-client:
dockerfilePath: src/client
redis-server:
dockerfilePath: src/serverWhat about pushing one of them to the dockerhub and the other one to your private registry?
redis-client:
dockerfilePath: src/client
registry: dockerhub
redis-server:
dockerfilePath: src/server
registry: private-registry.company.orgAfter Roger has created your new Docker image, before pushing it to the registry, you might want to run some tests:
redis-client:
dockerfilePath: src/client
registry: dockerhub
after-build:
- make testand, after all of this, you might also want Roger to send you an email:
redis-client:
dockerfilePath: src/client
registry: dockerhub
after-build:
- make test
notify:
- emailSesAWS SES is going to be used for sending emails,
and you only need to configure it on Roger’s config.yml:
notifications:
emailSes:
accessKey: 1234
secret: 5678
region: eu-west-1
to:
- john.doe@gmail.com # a list of people who will be notified
- committer # this is a special value that references the email of the commit author
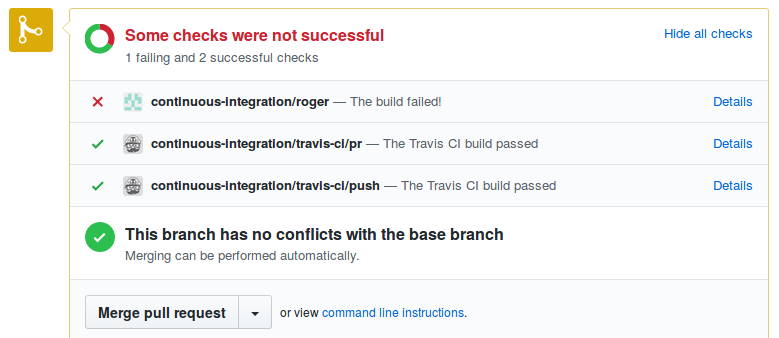
from: builds@company.com # sender email (needs to be verified on SES: http://docs.aws.amazon.com/ses/latest/DeveloperGuide/verify-email-addresses.html)At the same time, if your workflow happens through Pull Requests on github, you might want Roger to give you a heads up:
redis-client:
dockerfilePath: src/client
registry: dockerhub
after-build:
- make test
notify:
- emailSes
- githubWhich results in something like this:
For a more detailed overview, check the
configuration reference:
Roger can also upload assets to S3 and create revfiles for you
(revfiles are files containing informations about the version that
has been built, so that once you deploy your app you can expose them
at https://app.com/revision and see what’s running in production).
Roger in production
We have been running Roger in production
for the past 6 months or so and are quite happy with it: everytime a developer pushes, we get our
builds ready in seconds (or a couple minutes, if the projects is super-heavy!):
if there is a glitch while running a build, the developer goes to
github, open his PR and comments with build please! and Roger triggers
that build again. It’s that simple.
If I compare Roger to our old build pipeline, which was based on Jenkins, it feels like day and night: we had to configure jobs directly on the jekins web interface, copy them over when we had a new project etc etc. We wanted this to be smart and with (almost) zero overhead, and we’re happy where we got so far.
The road ahead
We don’t have a masterplan for Roger: it works very well for us and we do not intend to bloat it or “push it to the next level”: we think great software gets born from straightforward use cases, takes advantage of other tools and stays simple — these are the 3 basic rules we have been following while developing it.
Open-sourcing Roger means that you can now run your own Docker builds, for free, on your own infrastructure, thus saving on costs and time with a simple yet powerful solution.
Of course, we are also making it public so that you can hack on it: if you feel there’s something you hate about Roger, head to github and open a PR!
I don’t personally know what we’re going to be using in a year: CodeShip seems promising and we are actively experimenting with their private beta but, at the same time, having our build tool running on our premises looks like a very good solution; performances are great and we deploy it just like any other container we run in production.
Thanks to
I thought of mentioning 3 or 4 people that really helped with getting Roger where it is right now:
- Pedro Dias, who wrote the amazing dockerode that Roger uses to talk to Docker
- Armagan, who has been instrumental in getting Roger as straightforward and “automatic” as possible
- Shidhin, who gave Roger a face (its frontend), experimenting with ReactJS for the first time (parts of the perks of working at Namshi)
- the whole Namshi tech team, for being our beta-testers :)
All of these guys, with their collective effort, helped turning a 2-nights prototype into our build system.
Yallah!