Upgrading our search server towards high availability and beyond
In this post, we are going to highlight how and why we did a solr upgrade from solr v3 to solr-cloud v6 with no downtime.
We have adopted solr v3 as our search server since the beginning because solr has a nice schema and a very responsive search indexer. The old indexer was running on one solr server and whenever we needed to change the schema or trigger a full import we had to follow these steps:
- Unload the core
[SOLR_URL]/admin/cores?action=UNLOAD&core=[CORE_NAME] - Recreate the core with new schema changes, if any:
[SOLR_URL]/admin/cores?action=CREATE&name=[CORE_NAME]&config=[solrconfig.xml]&schema=[schema.xml] - Delete and then then re-import all documents
- Commit the updates
[SOLR_URL]/update?commit=trueto see it effective
The major drawback with this approach is that if the solr machine down it takes time to boot up another machine and re-import all the products again.
How do we handle our solr updates?
Partial imports:
Happens periodically: get the latest updates from DB and then update/delete only the changed documents in the given time frame.
Full imports:
Happens on request or on schema update: clear the indexer completely then insert all available documents.

Solr has lots of improvements and by using Solr-cloud in case of any solr instance failure we are not screwed.
The new structure is a solr cluster, and contains 3 zookeeper nodes with 2 solr cloud nodes.

How do we handle the solr clients app during transition with confidence and no downtime on live environment?
- We built a nodeJS service to handle periodic solr imports. The Zindex library is used to import data from mySQL (backend source) to solr.
- We kept the old solr server running side by side with the new solr on live environment.
- We made a change in our product catalog API that allowed us to return a response using the new or old solr, by simply using a special parameter. This allowed us to compare results coming from the old and new solr.
- Finally, we switched catalog requests to use the new solr one locale at a time till all supported locales were served with the new solr.
During the upgrade we faced some challenges – we are listing them below and how we dealt with them:
How to revert unwanted updates?
After a full import we tried to run some validations to accept or reject the import, since solr supports rollbacks! But we were disappointed because solr cloud mode doesn’t support rollbacks We solved this issue by saving the import in temporary files, running validations on these files, then commit
How to swap collections?
Another issue we faced was that during the full imports the product count in our catalog API decreased significantly, then increased slowly till the import finished. The reason behind this is that we were deleting all products during the full import, then re-adding the products so solr would show updates as fast as possible. To solve this issue we were thinking about swapping but this, again, was not supported in solr cloud So instead we used collections alias – every time we need to do a full import we create a new collection and after the updates and validations are done, we change the alias and delete the old collection.
## Get the current collection OM-1
curl [SOLR_HOST]/solr/admin/collections?action=LIST
#
#{
# "responseHeader": {
# "status": 0,
# "QTime": 0
# },
# "collections": [
# "OM-1"
# ]
#}
## Create the new collection OM-2
curl [SOLR_HOST]//solr/admin/collections?Action=CREATE&name:OM-2
## Create the new data file and post it to the new collection
curl -XPOST -d @updates.json [SOLR_HOST]/solr/OM-2/update
## Override the alias to point to the new collection OM-2
curl [SOLR_HOST]/solr/admin/collections?action=CREATEALIAS&collections=OM-2&name=OM
## Delete the old collection
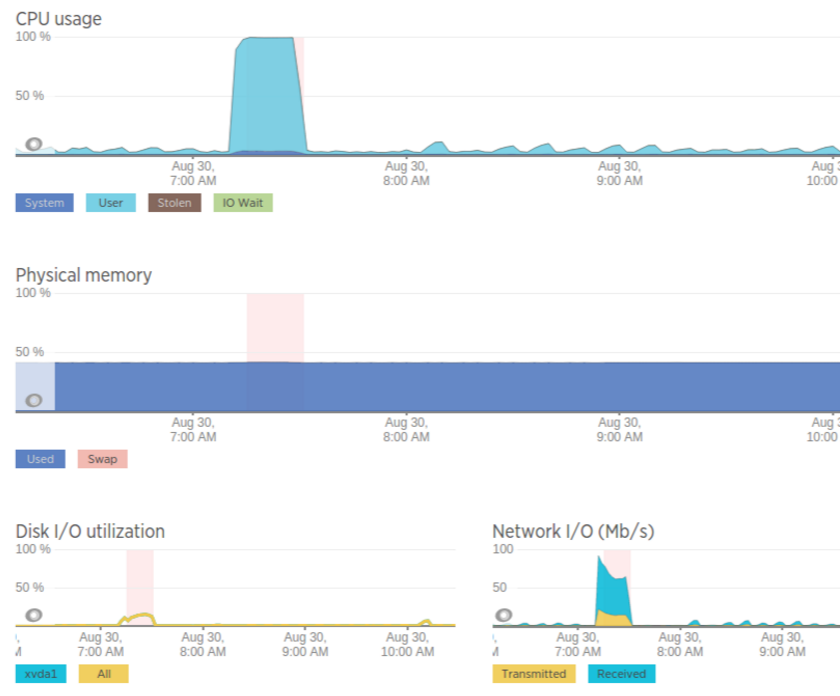
curl [SOLR_HOST]/solr/admin/collections?action=DELETE&name=OM-1&wt=jsonHow to do a full import for all collections without causing high CPU usage?
In our architecture we have a collection for each country and since all countries share similar documents with small variations, like price, we use one mysql source and fork the backend to import updates for each country (see Zindex) When we pushed updates for all countries in parallel, the solr CPU usage spiked and in order to solve this, we had to do the update synchronously with co
return prepareSolr(availableCountries, options).then(() => {
return co(function* () {
for(var i = 0; i < availableCountries.length; i++) {
var country = availableCountries[i];
var result = yield importProducts(country, options);
logger.info(`Solr Import has been finished for country ${country} with result`, result);
}
}).then(()=>{
logger.info(`All solr countries finished!`);
})
How to maintain solr cluster well?
Just like most of our services, we dockerize it. We have a monitoring script that checks the container status and another one that checks the app status e.g zookeeper replication status and solr ping, if any check fails we get an alert and apply the necessary fix.
